R y RStudio para Sciencia de los Datos
Este es el primer post de ERRE. Antes de comenzar a escribir código, creo que es necesario establecer bases sólidas que nos permitan aprovechar R al máximo. En este post hablaremos sobre las generalidades de R y RStudio y las ventajas de trabajar en este ambiente. Daré una introducción al uso de proyectos de RStudio para tener un ambiente de trabajo ordenado y hablaremos brevemente sobre las principales formas de ejecutar código. Finalmente, hablaremos sobre el uso de paquetes para extender la funcionalidad de R.
El ambiente de trabajo en RStudio
¿Cuál es la diferencia entre R y RStudio? Esta pregunta me la han hecho varias veces, y creo que es válido aclarar esta duda antes de comenzar con la parte del código. R es un lenguaje de programación con enfoque estadístico. R es el motor que ejecuta las operaciones que el usuario somete. Hay varias plataformas que permiten la comunicación usuarrio-motor. Una de ellas es utilizar R desde la interfaz de usuario de R:
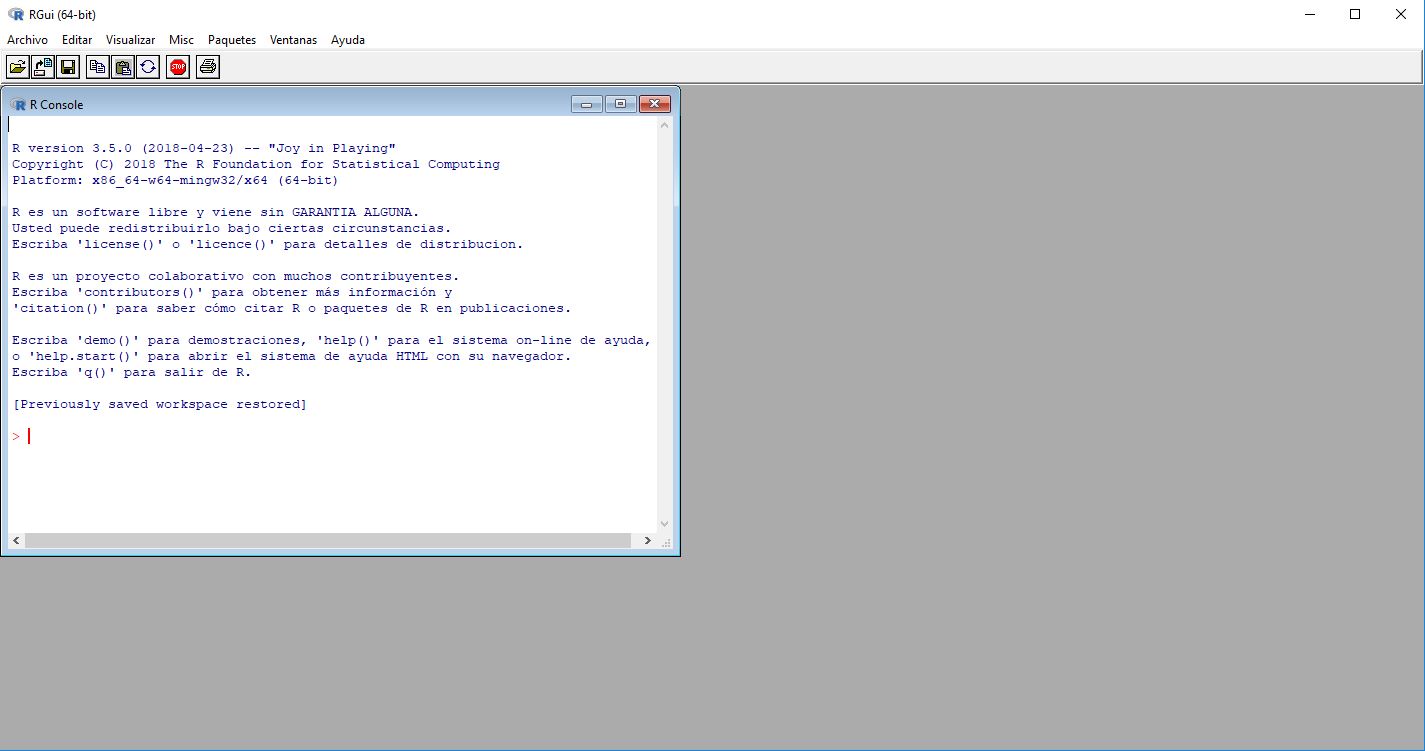
Aunque esta plataforma permite comunicarnos con R y hacer todas las operaciones, no brinda un ambiente de trabajo flexible. Como lo dice Hadley Wickham,
No se puede hacer data science desde una interfaz de usuario 1.
Es aquí donde RStuido se vuelve importante. RStudio es un Ambiente de Desarrollo Integrado (IDE, Integrated Development Environment). Esto quiere decir que expande la funcionalidad y flexibilidad de la interfaz de usuario. Esto es muy útil, pues nos evita tener que cambiar de ambientes para hacer diferentes tareas. En resumen, podemos integrar todo nuestro proceso de trabajo en un mismo ambiente. Esto además permite la replicación de análisis, resultados y productos (documentos, imágenes, presentaciones).
Puedes descargar R R y RStudio de manera gratuita. Una vez que los tengas instalados, puedes abrir RStudio y verás algo así:
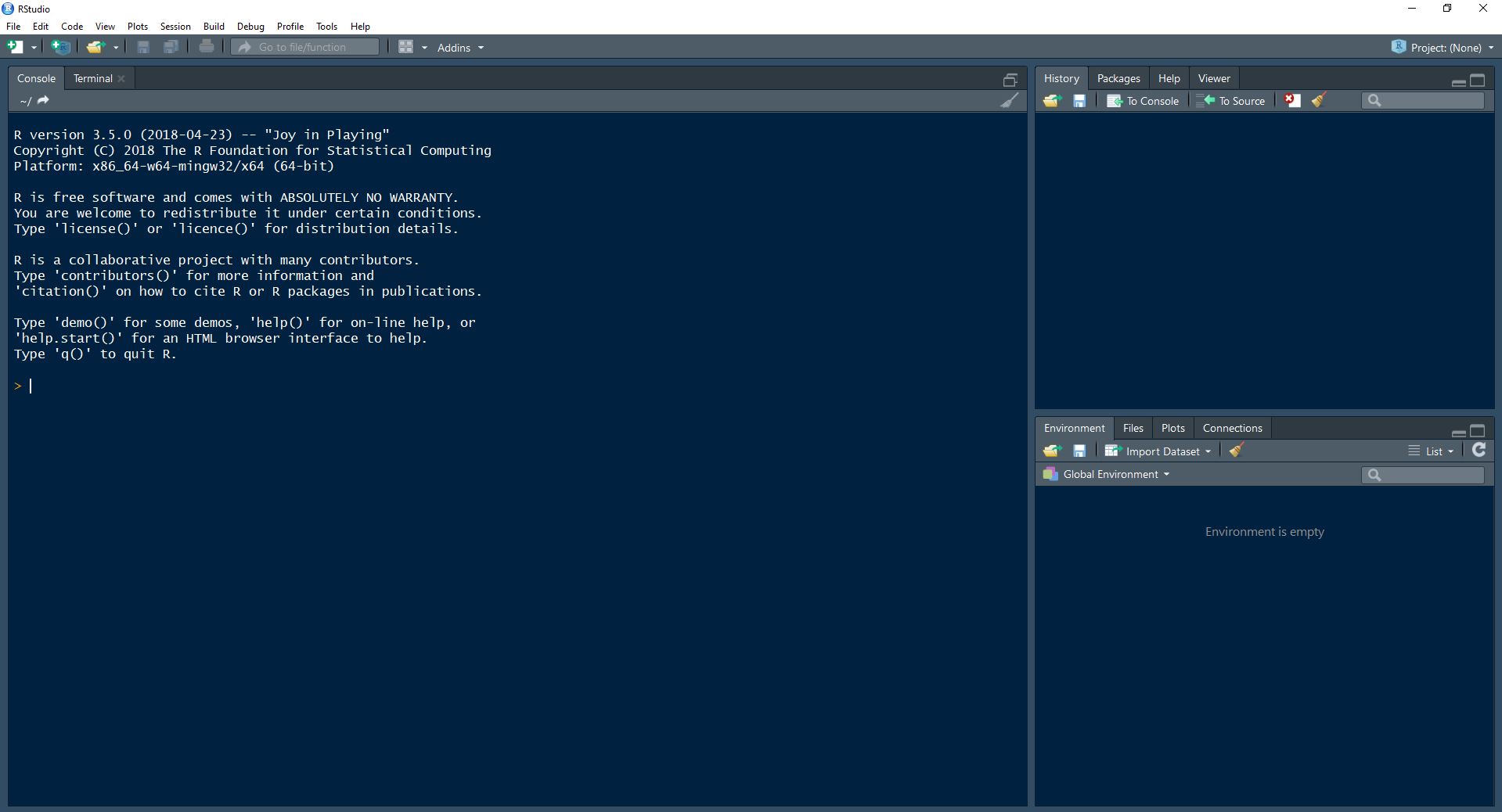
Notarás que hay más divisiones o secciones que en el RGui de la primera figura. En RStudio estas secciones reciben el nombre de páneles. Aquí hay un resumen de las partes principales:
Console: Aquí verás un cursos que parpadea a la derecha de un símbolo>y un cursor parpadeante. Escribe2 + 2y presiona la teclaEnter. La computadora responde diciendo[1] 4. Esta consola nos sirve para comunicarnos con R. Al pedirle la suma, R respondió diciendo que el resultado es4. Por ahora ignoraremos el valor de[1]que aparece a la izquierda.Environment: Este panel mostrará todos los objetos y variables generadas o cargadas. Por ejemplo, en la consola escribea <- 2 + 2y presionaEnter. Verás que esta vez R no respondió, pero en nuestro ambiente ahora hay una variable llamadoa, donde R almacenó el resultado de la operación. Si en la consola escribesay presionasEnter, R dirá:[1] 4. Toma nota que en R usaremos el operador<-para asignar valores a una variable.History: Este pánel te mostrará un historial de las operaciones anteriores. Si haces doble click sobre uno de los renglones, el texto se copiará a la consola para que puedas volver a ejecutar la operación. Desde la consola también puedes acceder a operaciones pasadas. Para esto, debes colocar el cursor en la consola y en tu teclado presionar la tecla que apunta hacia arriba. Cada vez que la presiones regresarás un paso atrás.Files: Aquí aparecerán los archivos que estén en el directorio de trabajo. En la siguiente sección hablaremos sobre como mantener archivos ordenados mediante el uso de proyectos de RStudio.Help: Este es probablemente uno de los páneles más útiles. Para conocer cómo se usa una función generalmente recurrimos a la documentación. Por ejemplo, la función para calcular el promedio de una serie de datos esmean()pero, ¿Cómo le especifico los datos para los cuales quiero el promedio? Puedes conocer más sobre losinputsyoutputsde una función escribiendo?meanen la consola y presionandoEnter. Esto abrirá la documentación de la función.
RStudio también te permite modificar el ambiente de trabajo. Puedes mover la posición de los páneles o modificar los esquemas de colores y el tamaño de fuente. Todas estas características las puedes explorar en la pestaña de Herramientas, bajo la sección de Opciones globales y Opciones de proyecto.
Investigación reproducible
Es importante que nuestros análisis y resultados puedan ser reproducidos y corroborados. Uno de los grandes avances de la humanidad es la capacidad de comunicar información por medio del lenguaje escrito, pues deja un legado que no requiere ser pasado de “boca en boca”. Escribir código nos permite comunicar nuestros procedimientos y contar una historia, pues el código no es más que texto. Aunque tiene su propia estructura, el código no es más que texto que puede ser comprendido por computadoras y humanos al mismo tiempo. Por ejemplo, el siguiente código es muy obvio para humanos y computadoras:
2 + 2Existen muchos lenguajes de programación, cada uno con sus reglas semánticas y gramaticales. No importa cuan complicado sea el código, la intuición es la misma. Al escribir código generamos una receta o bitácora explícita de nuestros procedimientos, permitiendo que sean replicados.
Además, podemos incluir mensajes que sean fáciles de leer por humanos pero que la computadora ignore. En R esto se hace con el uso del símbolo de número o hashtag (#). Todo el texto a la derecha de ese símbolo será ignorado por R, pero brinda información al humano que esté leyendo el código, por ejemplo:
# Sumamos dos más dos
2 + 2 # Tambien puedo comentar en la misma líneaComentar el código nos ayuda a explicar las operaciones que hacemos. Esto es útil al compartir nuestro código con alguien más, pero también al regresar a código viejo. Más de una vez he regresado a código viejo que no había comentado. Cada una de esas veces me he arrepentido de no haberlo hecho.
Proyectos de RStudio
Utilizar proyectos en R es una de las mejores formas de mantener un ambiente de trabajo ordenado. El proyecto mantiene un directorio de trabajo estable, donde mantenemos nuestros archivos asociados. El directorio de trabajo no es más que la localización de todos los archivos y carpetas. El comando getwd() (get working directory) te mostrará el directorio de trabajo. Si es la primera vez que abres RStudio o estás fuera de un proyecto, puede que el resultado sea:
[1] "C:/Usuarios/TuUsuario/Documentos"
Supongamos que mantengo todos mis archivos dentro de la carpeta de Documentos. Por ejemplo, asumamos que tengo dos proyectos de investigación. Uno es sobre peces rojos y otro de pájaros azules. Para cada uno de estos tendré archivos con datos, que mantengo separados en folders con la siguiente estructura:
C:/Usuarios/JC/Documentos/Proyectos:
|
-- PecesRojos/
| |
| -- datos/
| |
| -- peces_rojos.csv
|
-- PajarosAzules/
|
-- datos/
|
-- pajaros_azules.csvAdemás, dentro de Documentos tengo muchos otros archivos, ordenados y desordenados, que pertenecen a muchas otras cosas. Al trabajar en el proyecto de PecesRojos quiero asegurarme que todo lo que veo en mi pánel de Files son datos asociados a esto, sin ver datos de PajarosAzules o fotos de mis vacaciones pasadas. Para esto, usamos los proyectos de RStudio.
Estos son los pasos para crear un proyecto de RStudio:
- En la parte superior derecha de RStudio verás un ícono como este:
- Al hacer click, verás las siguientes opciones:
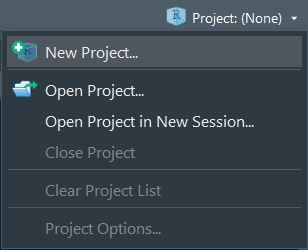
- Selecciona la opción de New Project y verás una nueva ventana así:
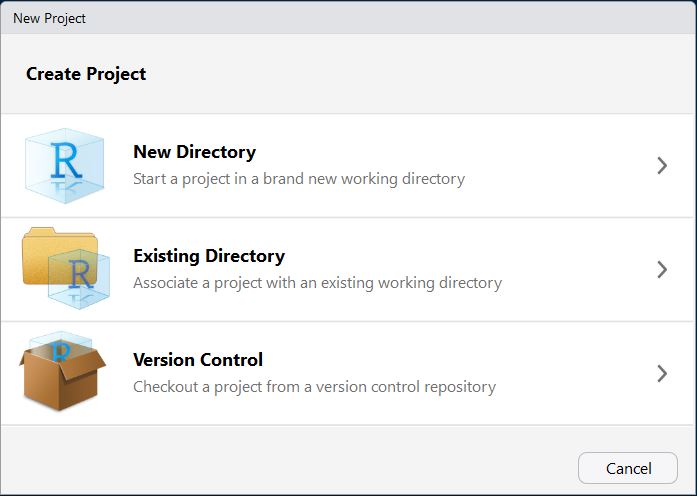
- En este caso, yo ya tengo carpetas con mis datos, por lo que seleccionaré la opción de Existing Directory. Al seleccionar esa opción aparece una nueva ventana, pidiéndome que indice el directorio al cual quiero asociar mir poyecto:
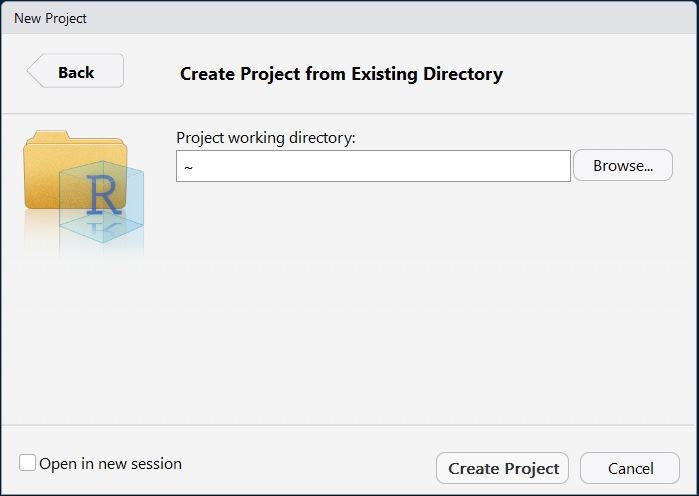
- Al hacer click en Browse se abrirá mi explorador de archivos, con el cual puedo navegar a
C:/Usuarios/JC/Documentos/Proyectos/PecesRojos
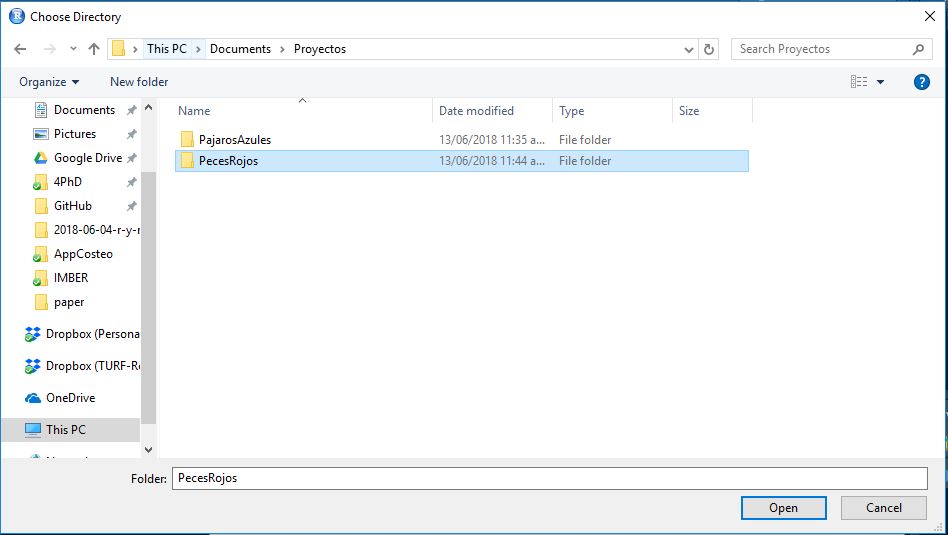
- Seleccionando el folder de
PecesRojosy dando click en Open la ventana del paso 4 ahora contendrá la dirección del directorio de trabajo:
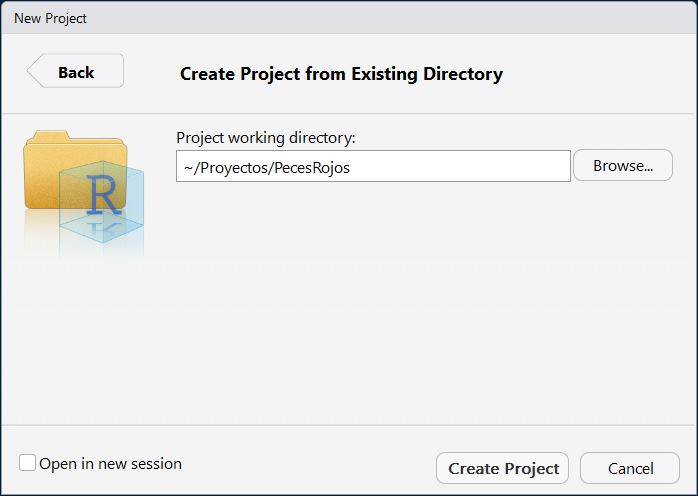
- Finalmente, hacemos click en el botón de Create Project y RStudio se actualizará.
¿Tantos pasos y todo se ve igual? No, al poner más atención verás algunas diferencias. Por ejemplo, la esquina superior derecha ahora dice PecesRojos, indicándonos que estamos en ese proyecto. La pestaña de Files mostrará la carpeta donde tengo los datos y un projecto de R llamado PecesRojos.Rproj. Además, el pánel con el historial de operaciones está vacío, pues no hemos ejecutado código en este proyecto. Lo más importante es que si ahora ejecuto el comando para obtener el directorio (getwd()) obtengo:
[1] "C:/Usuarios/TuUsuario/Documentos/Proyectos/PecesRojos"
Esto puede parecer trivial, pero tener un directorio asociado a nuestro proyecto nos permite cargar y guardar datos, figuras y tablas más fácilmente sin tener que estar cambiando el directorio. Estos temás se cubrirán más adelante en detalle. Por ahora, procura usar proyectos de RStudio para administrár mejor tu trabajo y mantener todo más ordenado.
Distribución de código
Como vimos anteriormente, podemos ejecutar comandos directamente en la consola. Sin embargo, la mayoría de las veces realizaremos varias operaciones simultáneamente y necesitamos tener tódo el código en un mismo lugar. Esto nos ahorra tener que escribir todas las operaciones cada vez, pero también nos da un documento que podemos archivar para futuras referencias o compartir. Aquí exploraremos dos formas de hacerlo.
Scripts
La forma más sencilla es con el uso de scripts de R. Estos no son más que documento de texto con extensión .*R en vez de *.txt. Para crear un script haz click en ícono de “Nuevo documento” y selecciona R Script:
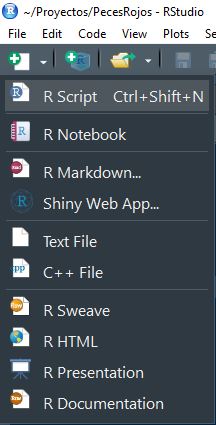
También puedes utilizar la combinación de teclas Ctrl + Shift + N. Esto abrirá un documento de texto vacío.
Tu ambiente en RStudio ahora debe verse similar a esto:
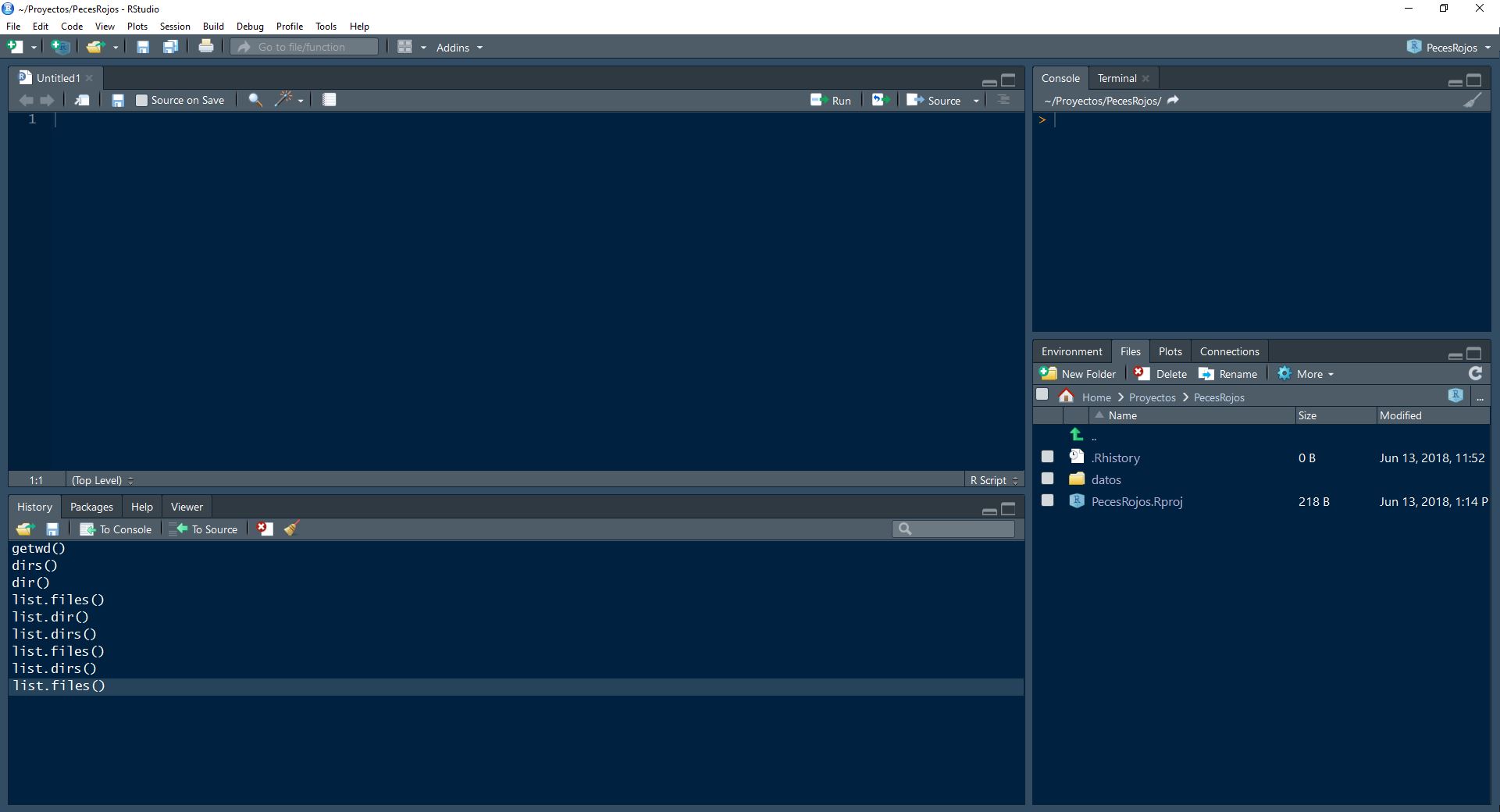
El panel superior izquierdo contiene el script, que dice Untitled1. Aquí podemos escribir varias operaciones seguidas, pero R no las ejecutará hasta que se lo indiquemos. Por ejemplo, el siguiente código genera una serie de 10 números almacenados en la variable num y después calcula el promedio, la mediana, la varianza y la desviación estándar. Todas estas funciones toman un input x, en este caso num y regresan el valor del estadístico calculado. Copia y pega el código en tu script.
# Este script calcula el promedio, mediana, varianza y desviación estándar de
# 10 números almacenados en la variable num
num <- c(1, 7, 2, 9, 0, 2, 4, 6, 8, 1) # Almacenar 10 números en la variable num
# calcular el promedio de num
mean(x = num)
# Calcular la media de num
median(x = num)
# Calcular la varianza de num
var(x = num)
# Calcular la desviación estándar de num
sd(x = num)Si presionas Enter, lo único que lograrás es agregar una nueva línea. Para ejecutar el código deberás colocar tu cursor al principio o al final de una línea y presionar Ctrl + Enter (También puedes hacer click en el ícono que dice Run en la esquina superior derecha del script). Prueba con la línea 4, donde creamos la variable num. Repite el proceso para las líneas 7, 10, 13 y 16. Notarás que en la consola aparecen los valores correspondientes a cada operación. Hasta ahora no hay mucha diferencia, pues seguimos ejecutando el código una línea a la vez.
Ahora, selecciona el código entero y presiona Ctrl + Enter o haz click en Run. Notarás que todas las líneas son ejecutadas automáticamente. Para guardar el documento, simplemente haz click en el ícono del disquete o “guardar”. Como con cualquier otro archivo, puedes guardar el R script en cualquier lugar de tu computadora. Como estamos utilizando proyectos de RStudio, yo sugiero crear una carpeta dentro de PecesRojos llamda scripts, donde mantendremos todos estos archivos.
Documentos de rmarkdown
Los documentos de rmarkdown también son documentos de texto, pero con extensión *.Rmd. Al igual que los scripts, estos nos permiten tener una serie de operaciones juntas. La principal diferencia es que un documento de rmarkdown se “teje” para generar archivos *.pdf, *.docx o *.html. Por ejemplo, este sitio entero está generado con rmarkdown. Más adelante tendremos un post dedicado al uso de rmarkdown, pero a continuación algunos detalles generales.
Crear un documento de rmarkdownes similar a crear un script. Sin embargo, seleccionarás la opción que dice R Markdown. Al hacerlo, deberás ver una ventana así:
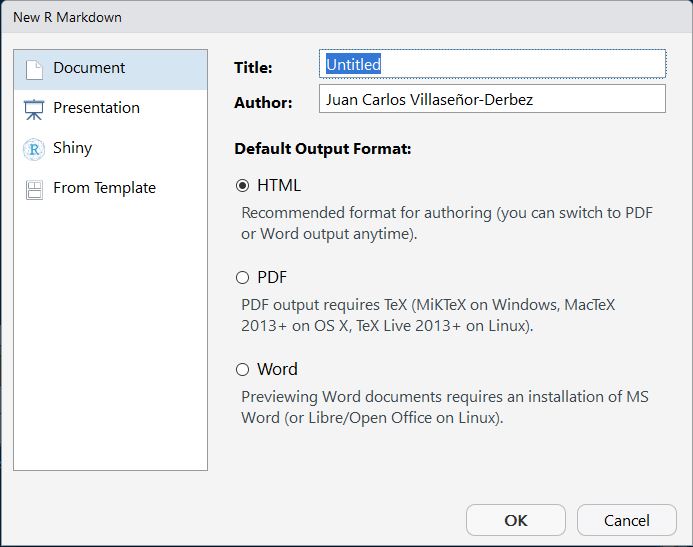
Ingresa un título para tu documento y, si quieres, un nombre para el autor. Selecciona la opción de HTML y da click en OK. Deberás de ver un documento con el siguiente código:
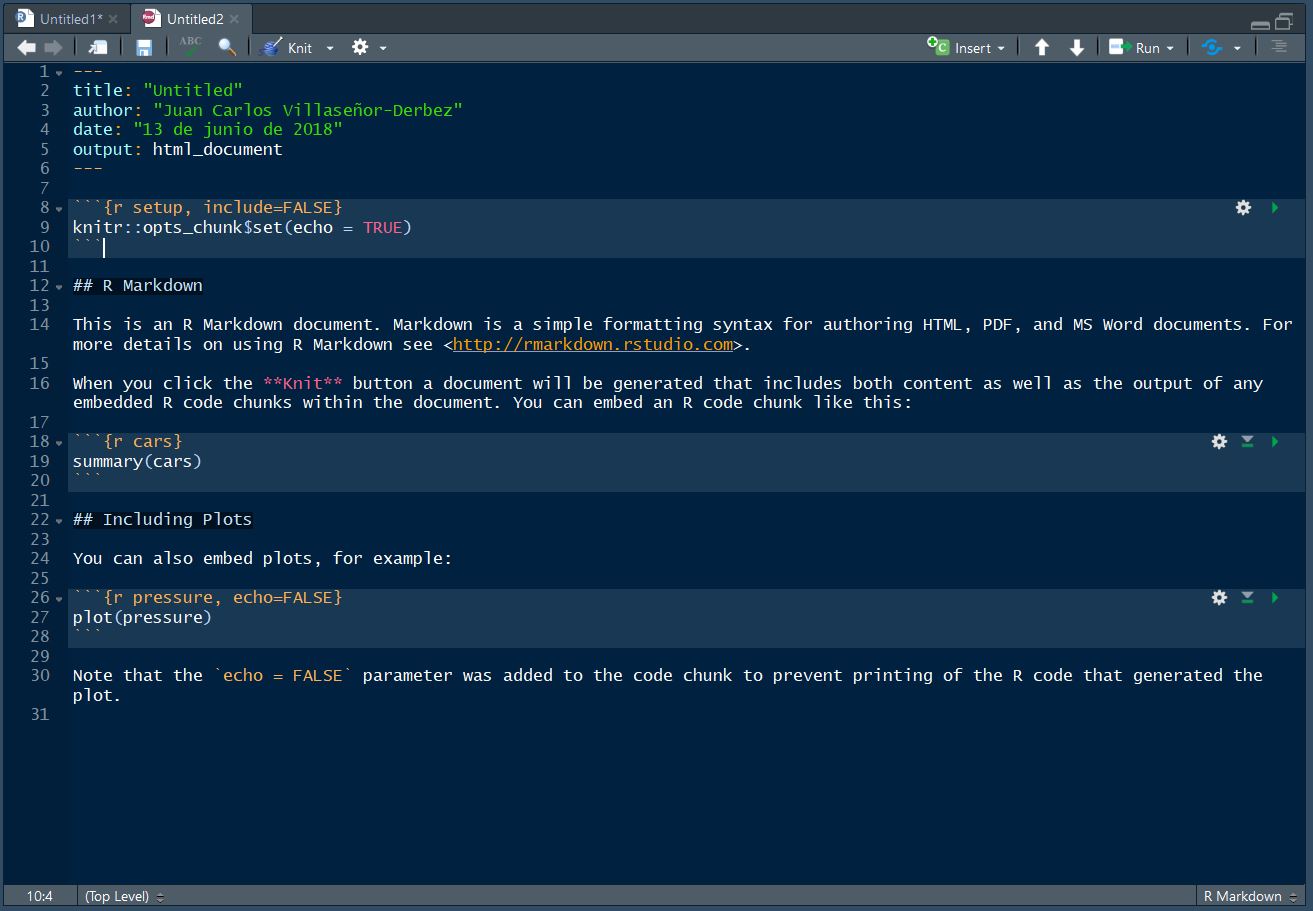
Notarás que en la parte superior se encuentra el título y nombre que ingresaste, además de la fecha y el tipo de formato a generar. Más abjo hay secciones con texto y código. Notarás que el texto no usa # para los comentarios. Esto es porque ahora separamos el texto del documento y el código usando code chunks. Estos se crean al presionar el botón que dice Insert en la esquina superior derecha del documento. Los chunks contienen el código a ejecutar, y todo lo que está fuera aparecerá como texto en el documento final. Si quieres incluir comentarios en tu código y que no sean visibles, puedes hacerlo dentro de los chunks.
Ve al cunk que dice summary(cars) y haz click en la flecha verde en el extremo derecho del chunk. Esto generará un resumen de los datos cars que están precargados en la memoria de R. Los datos contienen velocidades y distancias, y la función summary() calcula el rango, quartiles, mediana y promedio de cada variable.

Ahora, para aprovechar al máximo el documento, ve a la parte superior y da click en la bola de estambre que dice Knit (tejer).
R te pedirá que indiques un nombre del archivo. Al crear el documento especificamos el Título del archivo, que no necesariamente es el nombre del archivo. Piensa que el título podría ser “El Viejo y el Mar”, y el nombre del archivo libro_Hemingway.Rmd. Guarda tu documento dentro de tu carpeta del proyecto; a mi me gusta tener por lo menos carpetas distintas para datos, scripts y docs. Al guardar el documento, R ejecutará todos los chunks y generará un documento de *.html que contiene el texto, código, y resultados del código.
Ese documento de *.html contiene todas las imágenes generadas, por lo que puedes compartirlo directamente con alguien que no necesariamente trabaja en R y esta persona podrá abrirlo en cualquier explorador web. En el 98% de los casos, yo prefiero trabajar en un documento de rmarkdown y recomiendo que tú hagas lo mismo. Más adelante aprenderemos más sobre rmarkdown, como cambiar formatos de salida y como aprovechar al máximo esta herramienta.
Paquetes en R: base, stats y otros más
En la sección anterior utilizamos las funciones mean(), median(), var() y sd(). Como estas, hay muchas otras funciones directamente disponibles en R. Sin embargo, la activa comunidad de usuarios de R ha creado otras funciones con aplicaciones específicas. Estas funciones de distribuyen en paquetes, que pueden ser instalados. En el caso de las funciones anteriores, mean() pertenece al paquete base, mientras que median(), var() y sd() pertenecen al paquete stats. Todas las funciones pertenecen a un paquete. Para instalar un paquete nuevo (o la versión más actual de un paquete que ya tienes), utilizamos el comando install.packages(). Por ejemplo, copia, pega y ejecuta el siguiente código en tu consola:
# Instalar paquetes que usaremos en siguientes posts
install.packages(c("dplyr", "raster"))Este código instalará automáticamente dplyr y raster, dos paquetes con muchas funciones útiles que usaremos en siguientes posts. Una vez que la instalación haya terminado podemos cargar los paquetes. Aunque los paquetes ya estén instalados, es necesario especificarle a R que usaremos funciones de estos paquetes. Para esto, usamos el comando library(). El siguiente código carga los paquetes para que podamos usarlos.
# Cargar paquetes
library(raster)
library(dplyr)El comando install.packages() solamente lo utilizaremos cuando necesitemos instalar un paquete (por lo general, solo una vez). Sin embargo, library() lo usaremos cada vez que necesitemos usar un paquete.
En ocasiones dos paquetes distintos tendrán funciones con el mismo nombre. Por ejemplo, los paquetes dplyr y raster (que usaremos en siguientes posts) tienen la función select(). Esta función hace cosas muy distintas en cada paquete. El select() de dplyr selecciona columnas de un data.frame, mientras que el select() de raster sirve para obtener partes de una imagen satelital dibujando sobre una gáfica. Más adelante usaremos estas funcionalidades, pero por ahora el mensaje clave es que dos funciones de dos paquetes pueden tener nombres distintos. De ahora en adelante, cuando presente una función nueva especificaré el paquete del cual proviene utilizando el NAMESPACE, que se ve así: base::mean(). Esto indica que la función mean() proviene del paquete base. Al utilizar el NAMESPACE podemos saber de donde viene la función, pero también le indica a R que de todas las posibles funciones que tienen el mismo nombre, le estamos pidiendo que use una en específico.
Conclusiones
En este post aprendimos la diferencia entre R y RStudio, y algunas de las ventajas asociadas a trabajar en el Ambiente de Desarrollo Integrado. Hablamos sobre la importancia de usar código para comunicar y replicar análisis con otras personas y con nosotros mismos. Aprendimos como crear un proyecto de RStudio que nos permite organizar nuestro trabajo y mantener proyectos diferentes aislados. Después, hablamos sobre los formatos que se pueden utilizar para compartir código, y la utilidad de rmarkdown para compartir texto y análisis en un documento unificado. Finalmente, hablamos sobre los paquetes en R, y aprendimos como instalar y cargar paquetes. Con suerte, estos temas te darán las bases necesarias para usar R y RStudio de manera más fluida en los siguientes blogs, donde nos enfocaremos más en la programación.
